How to Use Local LLMs to Auto-Rename Cluttered Download Folders Without Cloud Privacy Risks
How to Use Local LLMs to Auto-Rename Cluttered Download Folders Without Cloud Privacy Risks
A considerable number of users, particularly those who often work with documents, photos, and software files, have the ongoing challenge of managing a downloads folder that is packed with data. Because of the passage of time, filenames tend to become inconsistent, obscure, or duplicated, which makes organization difficult and decreases productivity. Traditional renaming solutions either involve human labour or depend on artificial intelligence algorithms hosted in the cloud, which may put the user’s privacy at risk. By allowing intelligent file renaming directly on your device, local large language models (LLMs) provide a powerful alternative. This eliminates the need to transfer data to other servers. By using this strategy, you will be able to maintain full control over sensitive information while also receiving intelligent and understanding choices for naming. Local LLMs provide a contemporary answer to an age-old issue by combining the automation of processing with an emphasis on protecting individuals’ privacy. It is possible to dramatically simplify your workflow by gaining an understanding of how to implement and utilise them properly. From a technical and practical standpoint, this article delves into the use of local artificial intelligence for the arrangement of files.
Acquiring Knowledge of Local Local Law Enforcement and Their Capabilities
Machine learning models that are local LLMs are those that are executed locally on your own computer rather than depending on distant servers. The abilities of these models include the processing of natural language, the interpretation of file content, and the generation of useful outputs such as summaries or filenames. The fact that they function completely offline, in contrast to cloud-based solutions, reduces the concerns associated with data exposure. They are able to infer context and automatically assign suitable names thanks to their capacity to analyse language included inside documents or metadata. As long as they are configured correctly, local LLMs are capable of handling batch processing activities, which makes them an excellent choice for renaming huge databases of files. Performance is dependent on the availability of system resources, including the central processing unit (CPU), graphics processing unit (GPU), and random access memory (RAM). As technology continues to improve its capabilities, the possibility of executing these models locally is becoming more and more feasible for people in daily life.
When it comes to file renaming automation, why privacy is important
When utilising cloud-based renaming programs, files are often sent to other servers for processing, which raises worries about the user’s privacy. During the process of transmission or storage, sensitive materials such as bank details, personal photographs, or private work files may be exposed to unauthorised public access. By guaranteeing that all processing takes place inside your own system environment, local ledger management systems reduce this danger. It is especially vital for professionals who deal with confidential or regulated information to keep this in mind. Not only does offline processing protect users’ privacy, but it also lessens their reliance on internet access and eliminates complaints about slowness. The amount of control that users have over the handling, storage, and processing of their data is increased. The implementation of this level of autonomy is in line with the rising concerns over the ownership of data and digital security in contemporary workflows.
Creating a Local LLM Environment on Your System and Setting It Up
Before you can start utilising a local LLM, you will need to ensure that your computer is set up with a compliant environment. The installation of a runtime framework that is capable of supporting model execution and the downloading of an appropriate language model are often essential steps in this process. The configuration of dependencies, the allocation of system resources, and the optimisation of performance settings are all possible options throughout the setup process. For systems that have limited hardware, it is advised to use lightweight models, while more powerful setups are able to handle bigger models with more precision. It is possible to access the model using command-line tools or to include it into scripts after it has been installed. A correct configuration guarantees a smooth execution and reduces the number of mistakes that occur during file processing operations. Taking the time to carefully establish the environment is very necessary in order to get outcomes that can be relied upon.
Planning Your Download Folder for Artificial Intelligence Processing
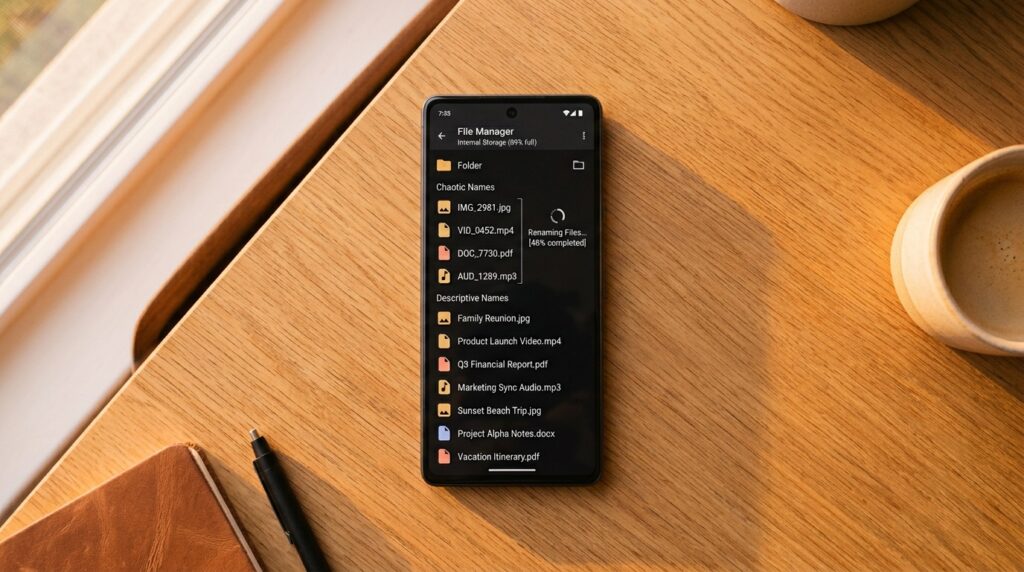
The preparation of your downloads folder is an essential step to do before beginning any kind of automatic renaming procedure. In order to do this, it is important to eliminate duplicates that are not required, organise files into fundamental categories, and verify that the file extensions are correct. The accuracy of the name recommendations provided by the LLM is improved when the input data is clean. The context that the model is able to analyse is improved when it is provided with files that include readable material, such as PDFs or text documents. Enhanced name accuracy may also be achieved by the use of metadata for media assets. Further streamlining of processing may be achieved by arranging files into subfolders according to their nature. With a folder that has been properly prepared, the LLM is able to function more effectively and generate filenames that are consistent and relevant.
It is possible to connect the LLM output with file renaming by using scripts.
The procedure of renaming files is not handled automatically by local LLMs since they do not have an interface or script to do the task. Typically, users will either develop their own scripts or utilise scripts that already exist in order to provide the model the content or metadata of a file and get proposed filenames in return. The new names are subsequently applied to the files by these scripts, which make use of instructions at the system level. It is possible to accomplish automation via the use of batch processing, which involves the handling of several files in a single action. Users have the ability to set naming conventions using the customisability options, which may include the inclusion of dates, categories, or keywords. It is the smooth renaming that is made possible by the integration between the output of AI and the operations of the file system. When you have the appropriate script, the whole process becomes much quicker and requires no manual labour.
Enhancing Accuracy Through the Implementation of Prompt Engineering Tools
The manner in which the LLM is told to do out the work, to a considerable extent, determines the quality of the renaming of files. Crafting instructions that are both explicit and detailed in order to direct the output of the model is an essential part of prompt engineering. As an example, you may provide the model instructions to produce filenames that are succinct and descriptive depending on the content of the document. It is possible to dramatically enhance consistency by including restrictions such as character limitations, formatting styles, or keyword prioritisation from the beginning. Over time, iterative testing helps modify prompts, which ultimately leads to better outcomes. It is also possible to improve accuracy by modifying prompts according to the kind of file being used, since various file formats need varying levels of contextual comprehension. When it comes to maximising the effectiveness of local LLMs for this purpose, one of the most important factors is the effective design of prompts.
Considerations Regarding File Conflicts and Edge Cases
It is necessary for automated renaming systems to take into consideration the possibility of conflicts and edge circumstances. Problems might arise when there are duplicate filenames, file formats that are not supported, or files that contain very little material. Putting in place backup rules guarantees that the system is able to deal with situations like this without making any mistakes. For instance, preventing the overwriting of existing files may be accomplished by adding incremental numbers to duplicate names. Changes may be tracked using logging methods, which also provide users the ability to evaluate updates if they are required. When deploying the system to a whole folder, it is essential to first test it on a small batch before applying it to the full folder. Ensuring dependability and preventing data loss during automation may be accomplished via the robust handling of edge circumstances.
Adjusting the Workflow in Order to Achieve Continuous Database Management
Once it has been determined that the system is functioning well, it may be expanded into a continuous process for the management of incoming files. The renaming process may be triggered anytime new files are uploaded to the downloads folder, which can be monitored by automation tools by monitoring the folder. This establishes a system that is capable of self-maintenance, which ensures that your directory remains ordered at all times. There is further potential for efficiency improvement via the scheduling of activities or the integration with system-level automation services. This method not only maintains a clean and searchable file structure but also decreases the amount of human labour required over time. The local LLM technology will continue to advance, which will result in these processes being increasingly more reliable and accessible. Implementing a system that is scalable guarantees long-term efficiency and organization without sacrificing the confidentiality of the information.